在當今高速發展的科學與工程領域,高性能計算(HPC)已成為推動創新、解決復雜問題的核心引擎。為了滿足科研機構、高校及企業客戶日益增長的大規模并行計算需求,亞馬遜云科技(AWS)近期宣布了一項重要技術整合:將業界廣泛使用的開源作業調度系統Slurm正式托管并深度集成至其Amazon ParallelCluster云超算平臺中。這一舉措標志著AWS在構建靈活、強大且易于管理的云端高性能計算解決方案方面邁出了關鍵一步,為計算機網絡與科技領域的技術開發帶來了新的范式。
一、 技術核心:Slurm與Amazon ParallelCluster的強強聯合
Slurm(Simple Linux Utility for Resource Management)是一個開源、高可擴展的作業調度與集群管理工作系統,長期主導著全球頂尖超算中心和研究機構的計算資源管理。它以其卓越的可靠性、高效的資源管理能力和對復雜工作流的出色支持而聞名。
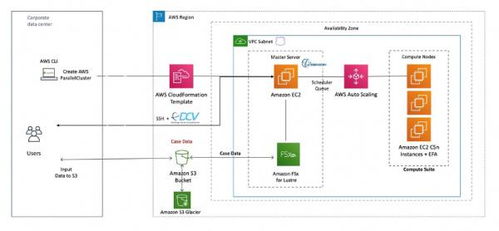
Amazon ParallelCluster則是AWS提供的一個開源集群管理工具,它允許用戶在AWS云上快速部署和管理具備自動伸縮能力的高性能計算集群。用戶通過簡單的配置文件,即可啟動一個集成了計算、存儲、網絡等資源的完整HPC環境。
此次技術開發的核心,是將Slurm作為一項完全托管的服務集成到ParallelCluster的架構中。這意味著AWS將負責Slurm控制節點的部署、配置、維護、監控和自動擴展,用戶無需再像過去一樣自行管理和運維調度器的基礎設施層。這種托管模式將用戶從繁瑣的集群管理工作中解放出來,使其能夠更專注于其核心的計算任務與應用開發。
二、 技術開發帶來的關鍵優勢
- 簡化運維與提升效率:托管Slurm服務極大地簡化了HPC集群的搭建與生命周期管理。用戶無需成為Slurm專家即可快速啟動一個生產就緒的集群。AWS自動處理補丁更新、安全加固和故障恢復,確保了調度器服務的高可用性與穩定性,顯著降低了運維復雜性和成本。
- 無縫的彈性伸縮:深度集成使得Slurm能夠與AWS的彈性計算服務(如Amazon EC2)以及ParallelCluster的伸縮策略無縫協同。集群可以根據作業隊列的負載情況,自動動態地擴展或收縮計算節點規模。這種“按需付費”的彈性模式,使得用戶能夠以最優的成本應對計算峰值,避免了傳統本地超算資源閑置或排隊等待的困境。
- 強大的生態系統集成:托管Slurm能夠原生地與AWS豐富的云服務結合。例如,計算節點可以輕松訪問高性能的并行文件系統(如Amazon FSx for Lustre),作業數據可以存儲在高容量的對象存儲(Amazon S3)中,同時可以利用AWS CloudWatch進行深入的監控和日志記錄。這為構建端到端的云上科研工作流和AI訓練流水線提供了堅實基礎。
- 保持開放性與兼容性:盡管是托管服務,AWS確保了與開源Slurm的API和命令行的高度兼容性。現有的基于Slurm的腳本、工作流和應用程序幾乎可以無需修改即可遷移到云上運行,保護了用戶的前期投資,降低了遷移門檻。
三、 對計算機網絡與科技領域技術開發的影響
這一技術整合遠不止于一項產品更新,它深刻影響著相關領域的技術開發模式:
- 推動HPC平民化與民主化:通過降低超算的使用門檻和管理負擔,更多中小型研究團隊、初創企業甚至個人開發者都能獲得媲美頂級超算中心的計算能力,從而加速各領域的研發創新,從基因組學、流體動力學到金融建模和影視渲染。
- 催化混合云HPC架構成熟:托管Slurm為構建靈活的混合云HPC架構提供了理想的控制平面。企業可以輕松地將本地集群與AWS云端爆發能力相結合,在保障核心數據安全的利用云端無限資源應對突發性計算需求,這已成為現代HPC架構的重要趨勢。
- 賦能AI與HPC的融合(HPDA/AI4Science):人工智能與高性能計算的結合是當前的前沿。一個由托管Slurm驅動的、彈性靈活的云超算平臺,正是訓練大規模AI模型、進行科學發現(如蛋白質結構預測、氣候模擬)的理想基礎設施。它能夠為復雜的多步驟工作流(模擬-分析-機器學習)提供統一、高效的資源調度。
- 促進云原生HPC應用開發:開發者可以基于此穩定、托管的調度平臺,更多地關注如何將應用程序優化以適應云環境的彈性特點,開發新一代云原生HPC應用,充分利用云服務的各種優勢。
###
亞馬遜云科技將托管Slurm引入Amazon ParallelCluster,是云計算技術與傳統高性能計算領域一次深度而務實的融合。它不僅解決了用戶在云上管理復雜作業調度系統的核心痛點,更通過云原生理念重塑了HPC資源的消費和管理方式。這項技術開發為全球的科研人員、工程師和開發者提供了一個更強大、更靈活、更經濟的高性能計算平臺,必將進一步激發其在科學研究、工程創新和商業洞察方面的潛力,持續推動計算機網絡與科技領域向更高效、更智能的未來邁進。